Scientific Workflow and Data Management with the Arvados Platform
I recently gave a talk at the recent Bioinformatics Open Source Conference (BOSC 2022) entitled: “Scientific Workflow and Data Management with the Arvados Platform”.
In making that talk, it struck me that this topic would also make a good blog post to describe my thoughts on the importance of workflow and data management and how we have incorporated such capabilities into the Arvados platform.
Reproducibility and Workflow Management
Reproducible research is necessary to ensure that scientific work can be understood, independently verified, and built upon in future work. Replication, validation, extension and generalization of scientific results is crucial for scientific progress. To be able to confidently reproduce results, you need a complete record of computational analysis you have done.
One of the major goals of the Arvados Project is to create a 100% open-source platform designed to help users automate and scale their large scientific analyses while ensuring reproducibility. We want users to be able to easily repeat computations, reproduce results, and determine the provenance of data (i.e. tracking any data from raw input to final result, including all software used, code run, and intermediate results.)
Some examples of reproducibility issues include:
- “We’re working in the cloud. Everyone has access to the S3 bucket, but to find anything you have to go ask Jane who has the whole directory tree in her head”.
- “I tidied up the project files a bit, and now the workflow stopped working with ‘File not found’ error.”
- “I re-ran the workflow but I’m not getting the same results, I can’t tell what changed.”
Problems with Conventional File Systems and Object Storage
When you store data directly on a file system or object storage, you cannot reorganize data without breaking all old references to data and you cannot attach metadata to datasets. S3 supports tags, but tags are extremely limited and cannot be used to query for specific objects in the S3 API. Permission management is mostly per-file, and difficult to manage. The common workaround is to give everybody access to everything, and hope nobody deletes anything important by accident.
When you run scientific workflows on top of conventional systems like this, you inherit all of their problems.
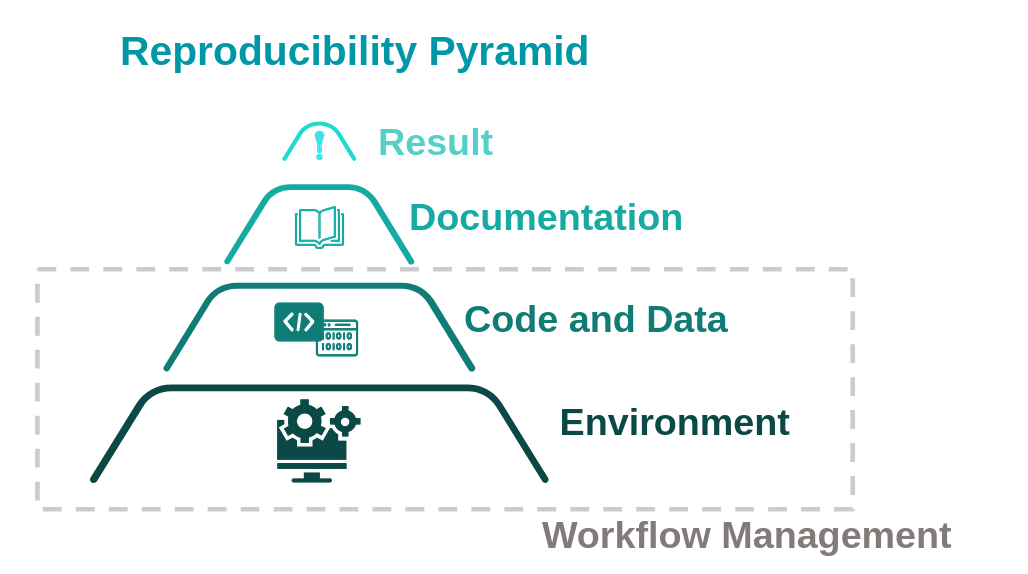
Figure 1: Diagram of multiple levels needed to produce reproducible results. Graphic modified from the work of Code Refinery
A large part of reproducibility involves “Workflow Management”. As illustrated in Figure 1, reproducible results rely on multiple levels that each contribute to reproducibility. The first two levels involve both the reproducibility of the code and of the environment. Combined, the management of both code, data, and environment can fall within the larger category of “Workflow Management” .
Workflow Management requires:
- keeping a record of workflow execution
- keeping track of input, output, and intermediate datasets
- keeping track of the software (e.g. Docker images) used to produce results.
Workflow Management inherently includes data management. Requirements of robust data management ideally include that all data should be identifiable at a specific point in time and/or by content.
The related data should be
- findable both through naming conventions, and searchable attached metadata
- associated with robust identifiers that don’t change when data is reorganized
- versioned to keep track of all data change
- secure and shareable
Arvados integrates data management (“Keep”) together with compute management (“Crunch”), creating a unified environment to store and organize data and run Common Workflow Language (CWL) workflows on that data. Major features of Arvados were designed specifically to efficiently enable computational reproducibility and data management.
Arvados File System and Collections
The Arvados content-addressable storage system is called Keep. Keep ensures that workflow inputs and outputs can always be specified and retrieved in a way that is immune to race conditions, data corruption, and renaming.
Keep organizes sets of files into a “collection”. A collection can have additional user metadata associated with it in the form of searchable key-value properties, and records the history of changes made to that collection. Data uploaded to Arvados is private by default, but can be shared with other users or groups at different access levels. To store data in a collection, files are broken up into a set of blocks up to 64 megabytes in size, which are hashed to get an identifier which is used to store and retrieve the data block. Collections can be then referenced by this content address (portable data hash) so later reorganization of input and output datasets does not break references in running workflows.
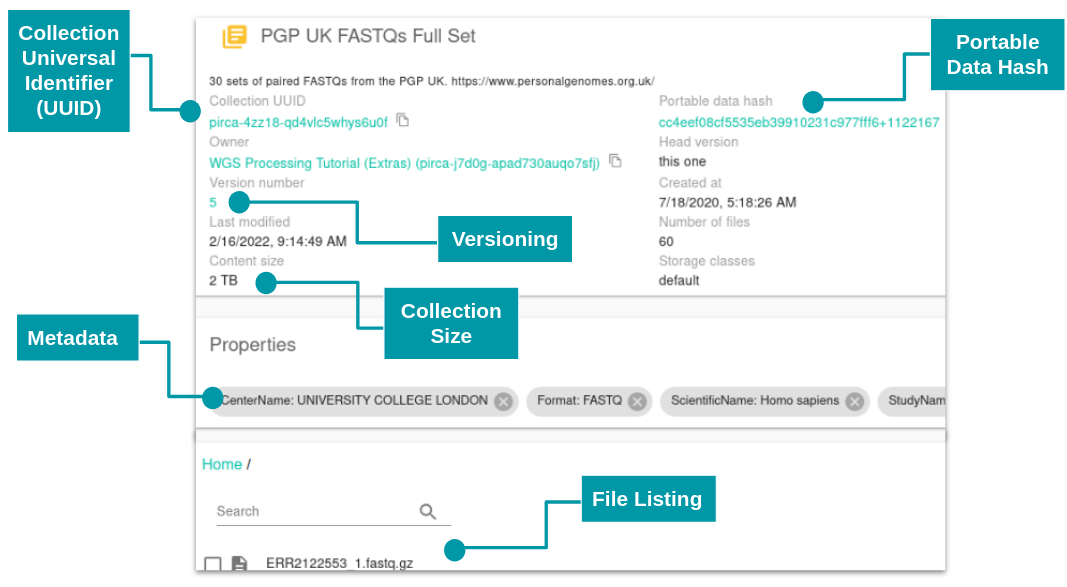
Figure 2: A ~2TB Arvados collection viewed in Workbench 2. The universal identifier (UUID), portable data hash (PDH), collection size, version, metadata and file listing are easily accessible.
An added benefit of the Keep is that it provides de-duplication, as the same data block can be referenced by multiple collections. This also means that it is cheap to copy and modify collections, as only the block identifiers need to be copied and not the actual data. You can learn more about how keeps works at this blog post, A Look At Deduplication In Keep.
When a workflow is run in Arvados, the entire workflow execution is stored in collections. This includes inputs, outputs, steps, software (Docker images), and logs allowing for full traceability of your executed workflows. Arvados can check if an identical step in a workflow has already been run and then reuse past results, so re-running a workflow where only certain steps have changed is quicker and more efficient. Without automated features to support this optimization, informaticians are tempted to make such decisions manually, a practice which is error-prone and therefore often wastes more time than it saves.
Workflows and Standardization
Storing data in standardized formats is extremely valuable. It facilitates sharing with others, using the same data with different software, and the ability to use old datasets. Similarly, standards for writing workflows are extremely valuable. A standard for sharing and reusing workflows provides a way to describe portable, reusable workflows while also being workflow-engine and vendor-neutral. Arvados supports the Common Workflow Language (CWL), an open standard used and supported by many organizations. It facilitates sharing and collaboration, has multiple execution engines, and a commitment to a stable definition.
Using Metadata and Freezing Projects
Arvados administrators can set up a formal metadata vocabulary definition, enforced by the server. In the user interface, users are given a list of predefined key/value pairs of properties. For more information, visit the documentation.
Starting in Arvados 2.4.3, Arvados now automatically records git commit details for workflows. When a CWL file located in a git checkout is executed or registered with --create-workflow or --update-workflow, Arvados will record information about the git commit as metadata for the workflow and use git describe to generate a version number that is incorporated into the Workflow name.
Starting in Arvados 2.5 you can freeze a project. A frozen project becomes read-only so that everyone (including the owner and admins) are prevented from making further changes to the project or its contents, including subprojects. This adds a layer of protection so that once a project is “finished” and ready to share with others, it can’t be changed by accident.
Summary
By combining both a data management and compute management system, Arvados enables researchers to analyze and share data while maintaining security and control, keep a record of analysis performed, and attach metadata to data sets to answer questions such as when, where, why and how a data set was collected.